


Datenentwirrung hyperfunktionaler Alltagstechnologien
Zur Wahrung des «Intellectual Property» (IP) wird auf die Gesamtvorstellung der Forschungsdetaillierungen zur algorithmischen Datenentwirrung hyperfunktionaler Alltagstechnologien öff. verzichtet. Einzig seien Fragmente derselben strukturell vorgestellt, anhand derer sich sonach die forschungswissenschaftlichen Verfahrensschritte plausibilisierend nachvollziehen lassen. Demungeachtet unterliegt auch diese Skizze dem Urheberrechtsschutz.
Präamel
Sprachverwirrung: allgemeinhin bekannt als die göttliche Sanktion gegen fortschrittliches Enthemmnis im altbiblischen Babylon. Es ist einerlei, ob das uns überlieferte Kommunikationschaos tatsächlich durch Jahwes Abstrafung menschheitlicher Vermessenheit und Selbstüberschätzung erfolgte, oder ob deren Konsequenz die Kapitulation vor der entglittenen Kontrollierbarkeit und Verstehbarkeit prähistorischer Superlative war. Es bezeugt uns jedenfalls in abschreckender Parallelität die Verwundbarkeit heutiger Entfremdung von unserem eigenen, überquellenden Erfindungskatalog. Unsere umfassende Abhängigkeit hiervon, ja die unseres Erdplaneten, unterstreicht das Erfordernis der Datenentwirrung hyperfunktioneller Alltagstechnologien.
[Vom «Turmbau zu Babel» sind heute kaum noch Reste erkennbar. Alexander der Große ließ rund Zweitausend Jahre später jene imperiale Tempelanlage zerstören, sodass sie Jahrhunderte lang noch als Steinbruch diente. Heute befindet sich dort ein Sumpfloch.]
Es waren also weder Kriege noch Naturkatastrophen, die zum Aus jener sog. hochzivilisierten „Vorzeitmoderne“ führten, sondern schlichtweg das aus ihr entwachsene Verständigungschaos. Dieses wiederum wurde durch den (uns gleichsam heute ereilten) Überblickverlust abhängig machender Erfindungsvielfalt bewirkt, insofern deren unverzichtbarer Kontrollierbarkeit und Verstehbarkeit zu wenig Gewichtung beigemessen wurde/wird. Der Verlust forschungswissenschaftlicher Übersichtlichkeit spiegelt sich sowohl in politischen, finanziellen sowie industriellen Marktkapriolen wider, als auch in chaotisierten Überbietungen von oft pseudoinnovativen Lösungsideen unserer globalen Existenzprobleme. FEAT hat eine intensionale Begriffsvereinheitlichung geschaffen. Die Überfülle an teils seltsamsten, für den gemeinen Menschen selbst oft nicht mehr verstehbaren Begriffen, wird durch sinnvolle Verdolmetschung neu katalogisiert. Hierbei werden immer auch gemeinsame Merkmale funktioneller Alltagsgegenstände auf einen – weitestmöglich gemeinsamen – Begriffsnenner gebracht, indem deren Funktionalität für den Endverbraucher vom Prinzip her nachvollziehbar und begreiflich benannt wird.

Wo Unternehmen sich fernerhin gezwungen sehen, ihre eigene Begriffswelt zu erschaffen, formuliert FEAT die einende Schnittstelle, indem von extensionaler zu einer intensionalen Begriffsgemeinschaft geschritten wird, in welcher Produktions-, Forschungs- und Innovationsarbeiten effizienter werden. Reinalgorithmisch ist dies in Gestalt diverser mathematikprozessualer Informationstransfers via Matrixvektormultiplikationen darstellbar (s. u.s. Formel). Zu näherem Verständnis: ≈ 4 Milliarden Internetnutzer jagen Tag und Nacht, rund um die ganze Erde, teils völlig ungefiltert, meist spontane Gedankenfetzen nebst Gefühlsduseleien als irrwitziges Gebräu an Datenfluten in die Zentralrechner, um von letzteren zunächst algorithmisch erfasst und mathematisch präzise zugeordnet zu werden, bevor sie den jeweiligen Adressaten verlässlich zugestellt werden – immerzu binnen Millisekunden! Unterdes aber hat sich ein gigantisches Sammelbecken an Informationsdatenwust gebildet, welches nur noch mithilfe o.g. Algorithmischer Kläranlage entgiftet / entwirrt werden kann. Da fernerhin eine Taktzeit in normalen PC-Prozessoren aktuell bei ≈ 2 GHz liegt (also eine Fünfhundert-tausendmilliardste Sekunde für 1 Verarbeitungsbefehl), hingegen Licht binnen 1 Sek. siebenmal um den Erde reicht, zeitgleich aber rund um den Welt Abermilliarden derartiger Taktungen erfolgen müssen, wird das Naturgesetz hier gar zur „PC-Leistungsbremse“. FEAT hat hierfür einen zusätzlichen, Neun-Komponenten-Verschlüsselungsalgorithmus (den sog. Fledermausalgorithmus) entwickelt, welcher IT-Nutzer nicht nur besser vor Hackerangriffen schützt, sondern die Prozessorleistung zugleich x-fach gesamtheitlich steigert.
Zur Einstimmung:
legt man das „Mooresche Gesetz“ zu Grunde, so verdoppelt sich mindestens alle 1½ Jahre die Rechenleistung eines jeden Personal-Computers. Weil aber der Rechenleistungsbedarf die vorgesehene Kapazität jenes algorithmisch-automatisierten PC-Hirns (gen. Prozessor) längst schon gesprengt hat, blieb den großen Computerbauern -spätestens nach Nine-Eleven- nichts anderes übrig, als bald immer mehr solcher Prozessoren in einen PC zu verbauen, welche darin allesamt immerzu parallel arbeiten bzw. rechnen müssen. Zum besseren Verständnis folgender Vergleich: man stelle sich vor, ein Dr. Sciencefiction würde in unseren ohnehin chronisch überlasteten Kopf irgendwann mehr und mehr Parallelgehirne bzw. parallel arbeitende Hirnzentren transplantieren. Ergebnis: der Mensch dreht durch... stirbt! Nachdem wir unsere gedankliche Kraftanstrengung aber zusehends derartigen „Ersatzhirnen“ (Computern) übertragen, also auf Gutglauben „outsourcen“, führte solch Überstrapazieren bzw. Überschreiten grundphysikalischer Grenzen schließlich zur sprichwörtlichen „Quadratur des Kreises“.
Wenn ich hier, an meinem kleinen Arbeitsplatzrechner also, Überlegungen zu einer interkommunikativen Datenentwirrung hyperfunktioneller Alltagstechnologien anstrenge, darf ich noch davon ausgehen, dass in meinem PC eine überschaubare Anzahl von Parallelprozessoren (Kernen, allg. bekannt als dual-core, quad-core) arbeitet. Ganz anders bei sog. Supercomputern, wie sie Kreditinstitute, Kliniken, forschende Unternehmen, Konzerne u.dgl. alltäglich beanspruchen. In solchen Großcomputern nämlich stecken bereits so irrwitzig viele Prozessoren, sodass es Hackern immer leichter fällt, Einfallstore in hochsensible Datenbanken aufzustöbern. Man vergleiche dies mit einem überstrapazierten Menschenhirn, welches logischerweise deutlich einfacher manipuliert werden kann, als ein kühler Menschenverstand.
Beispielsweise hat der Marburger Rechencluster MaRC momentan knapp 600 Rechnerkerne, während in geheimdienstlichen RCs jeweils mehr als eine Viertelmillion solcher Parallelprozessoren ineinander gepfercht arbeiten. Der fast schon tsunamiartig anschwellende Leistungszuwachs aber ist v.a. dem Anspruch auf immer kleiner, immer feiner auflösende Virtualisierung von im Grunde realen Alltagsproblemen geschuldet: Marktforschung, Marktanalysen, Marktentscheidungen, Meinungsforschung, Meinungs-bildung, fernerhin Erdbeben- und Vulkanberechnungen, Wettervorhersagen, Klimamodellierung, Erderwärmungssimulationen, Multimarketing, Geldtransfers aller Art, ja Cyberwahn-sinn – Terroristenerkennung und Terrorabwehr, Wahlkampagnen, etc., die Kette unterschiedlichster Wunschformen von Daten- und Informationstransaktionen reißt nicht ab.
Vergessen seien unterdes keinesfalls die bereits über 3,3 Milliarden Internetnutzer, welche ihrerseits zu jeder Tages- und Nachtzeit, rund um den Erdball, völlig ungefiltert, gern auch spontane Gedankenfetzen nebst Gefühlsduseleien als irrwitziges Gebräu an Datenfluten in Zentralrechner jagen, um von letzteren zunächst algorithmisch erfasst und höchstpräzise geordnet zu werden, bevor sie den jeweiligen Adressaten verlässlich zugestellt werden – und all dies immerzu binnen Millisekunden! Hier aber sind längst ganz neue Algorithmen vonnöten – FEAT wird solche erarbeiten und anwenden helfen: Vorangestellt sei anhand nachstehender Graphik folgender Zusammenhang n = m(hoch d) für m = 4.

Da wir aus vorgenannten Gründen heute praktisch nur noch mit Parallelrechnern arbeiten, entsprechen deren Leistungsangaben kaum mehr der Realleistung. Zwar vergibt der Hersteller gem. berechneter Spitzenleistung (peak performance) eine Art „Leistungsgarantie”, welche i.d.R. jedoch niemals wirklich erreicht werden kann, da dieser so tut, als würde der Rechner alle Einzelleistungen zeitgleich maximal erbringen können. D.h., hier werden einfach alle Einzelleistungen zusammenaddiert, so als würde für jede Einzelleistung ein jeweils eigener Rechner vorgesehen sein – was bekanntlich Quatsch, wenn nicht eine dreiste Lüge ist!
Zur näheren Erklärung: gleichzeitiges Be-/Verarbeiten von Aufgaben erfordert umso höheren Leistungs aufwand fürs algorithmische Koordinieren und aufeinander Abstimmen von jeweils völlig unterschiedlichen Leistungsansprüchen desselben Rechners. Stellen wir uns hierzu stark vereinfacht das Computerinnere vor: Der Rechner, so wie er ursprünglich mal konzipiert worden ist, besteht neben der Zentralrecheneinheit (CPU, Central Processing Unit), aus einem Speicher – Ein- und Ausgabe nicht berücksichtigt. Im Speicher stecken sämtliche zu verarbeitenden Daten sowie das verarbeitende Computer-programm selbst. Die CPU ist ferner mit einer Art Taktgeber ausgestattet, mit dessen Hilfe die einzelnen Verarbeitungsschritte strukturiert werden können. Eine CPU kann ihrerseits immer nur eine einzige Programmanweisung erteilen und zugleich ausführen, wiewohl sie fraglos auch verschiedene Taktzyklen auf einmal zu beanspruchen vermag. Hier, also im ursprünglichen Computer, operierte die CPU immerhin noch mit Daten aus recht wenigen und kleineren Lokalspeicherplätzen, den sog. Registern, sowie mit Datenbündeln aus dem Haupt-Speicher. Unterdes ist der Speicherzugriff ebenfalls getaktet, wenngleich mit längerer Zugriffszeit. Da aber jedes Signal innerhalb eines jeden Taktes in ganzer Ausdehnung die CPU erreichen muss, wird hier gar die Lichtgeschwindigkeit zur „physikalischen Bremse“ jener Taktungen (immerzu abhängig von der jeweiligen Chipgröße).

Aktuell liegt eine Taktzeit in normalen PC-Prozessoren bei ca. 2 GHz. Mit anderen Worten: lediglich ein Verarbeitungsbefehl nimmt ganze 0,5 Nanosekunden in Anspruch, also eine Fünfhundertausendmilliardste Sekunde. Bedenkt man hier, dass allein das Licht binnen einer Sekunde siebenmal um den Erdball reicht, hingegen rund um den Globus zeitgleich Abermilliarden von derartigen Taktungen erfolgen. Resümierend darf festgestellt werden: Dem erhöhten Leistungsbedarf wurde bisher quantitativ vs. qualitativ entsprochen: Da in praxi nämlich beide Ressourcen, Speicher und CPU, gleichwertig empfunden und beansprucht werden wollen, entpuppt sich ausgerechnet die CPU, also das „Gaspedal“ des Datenvehikels als „Bremse“, indem sie wie eine Art Flaschenhals aufgrund der zu verarbeitenden Datenfülle chronisch „verstopft“ ist. Die ungleiche Lastenverteilung erfordert also eine Korrektur in der algorithmischen Rechnerarchitektur. Im Vergleich: ein Mensch, der sich zu gerne und intensiv des Multitaskings bedient, riskiert ein Burnout. Interessant ist hier wieder die leistungsüberstrapazierte Parallele zwischen Menschenhirn und PC-Prozessoren. Diesem Engpass könnte man folgenderweise entkommen: Diffizile Aufgaben werden auf Mehrere verteilt, wodurch Prozesse beschleunigt und Prozessoren ein Stück weit entlastet werden könnten. Aber anstatt eine algorithmische Aufgabenkoordinierung vorzunehmen, ist es offenkundig der sowohl bequemlichen als auch geizhaften Konkurrenzdenke des Herstellers geschuldet, dass man diese längst unfassliche Mehrbelastung globaler Datenverarbeitungen durch stupides „Hinzuklonen“ von endlos vielen Parallelprozessoren zu kompensieren versucht, unterdes sich aber ein gigantisches Sammelbecken an Informationsdatenwust gebildet hat, welches wiederum nur noch mithilfe matheprozessualen Ordnens in einer Art algorithmischer Kläranlage entgiftet und entwirrt werden kann. Vgl. Abb. praktizierter Klonmethoden:

Nochmals zur Erklärung: unsere Arbeitscomputer verfügen i.d.R. über einen gemeinsamen Arbeitsspeicher. Auf diesen greifen die einzelnen Prozessoren zu - mangels CPU-Leistungskapazität immerzu miteinander konkurrierend. Die Prozessoren sind ihrerseits als sog. Kerne (dual-core, quad-core) auf einem entsprechenden Chip untergebracht. Dort sind alle Daten für alle Prozessoren gleichermaßen abrufbar – und genau hier sitzt das Problem! Zwar können vereinzelt Koordinationsprobleme von Mehrfachdaten-zugriffen mithilfe einer ziemlich teuren Zusatzhardware gelöst werden, deren entwickelte Algorithmen sich hochleistungsstark aufs Parallelisieren resp. Verschlanken der einzelnen Aufgaben konzentrieren. Dieser „Trick“ funktioniert nur in überschaubarem Maße.
Im Vergleich: ein Mensch, der mehrere Baustellen zugleich zu bedienen hat, kann dies oft nur unter Zuhilfenahme von Aufputschmitteln. Durch erhöhte Leistungsstärke mithilfe jener teuren Zusatzhardware sind die Prozessoren infolge auch schneller „ausgelaugt“. Auch hier wieder parallele Eigenheiten unseres menschlichen Gedankenapparats zu unserem sprichwörtlich erfundenen „Ersatzhirn“ namens Computer! Im IT-Fachjargon sind vorgenannte Hardware-Ergänzungstypen auch als Multiprozessor-systeme bekannt. Bei einer Vielzahl an Prozessoren wird jedem Prozessor ein eigener (verteilter vgl. Abb.) Speicher zugeordnet. Der o. e. Marburger Cluster (MaRC) besteht bspw. aus über 140 Quad-Core-Prozessoren.
Da diese Architektur aber immense Leistungsanforderungen an das verbindende Netzwerk zwischen den Prozessoren richtet, müssen aufgrund gefrönter Parallelalgorithmen inzwischen nicht nur die Arbeiten bzw. jeweiligen Aufgaben, sondern auch die Daten auf die verschiedenen Prozessoren verteilt werden. Das muss man sich mal vorstellen: Leistungsträger werden zur Datenspeicherung missbraucht, nur, weil man die Datenübermenge als scheinnotwendig hinnimmt und so behandelt, als wäre sie sämtlich mit einzigartigem, ja unverzichtbarem Informationsinhalt bestückt. Dadurch nämlich, dass durch stumpfsinnige Parallelalgorithmen die allermeisten Daten mit austauschbaren Informationsinhalten - infolge ihrer Übermenge - die wichtigen Leistungsträger regelrecht „zukleistern“, werden auf Dauer umso mehr Parallelprozessoren vonnöten sein. Schneeballeffekt!
Im Grunde entspricht diese Architektur auch der Systemvariante «Internet», dort allerdings noch vermüllter, unübersichtlicher dank parallelalgorithmischer Quantenverarbeitung, d.h., Quantität vs. Qualitätsanspruch. Hinzu kommen derweil noch ganz andere Probleme, nämlich dass Milliarden von Internetnutzern meist unterschiedlichste Betriebssysteme mit obendrein ganz unterschiedlichen Leistungen für Ihren Datentransfer benutzen – was nicht zuletzt auch das Entwickeln eignungsfähiger Algorithmen erschwert. Als Ad-hoc Lösung könnte man die heutigen Arbeitsrechner dahingehend umrüsten, insofern jeder Zugriff auf den Speicher immerzu langsamer als die Taktung der CPU verläuft, und jeder Prozessor P vgl. folg. Abb. neben seiner Recheneinheit R Abb. noch einen kleineren Cache-Speicher C Abb. hinzubekäme. Auf diesen könnte der Prozessor sodann deutlich rascher zugreifen könnte, als bislang immer nur auf den Haupt-Speicher. So bekäme man zumindest kurzfristig die überflüssigen Datenklumpen von den überlasteten Prozessoren herunter.

In praxi würde man so sämtliche aus dem Hauptspeicher P abgerufenen Daten im Cachespeicher C zwischenspeichern können, um bei späterem Gebrauch sofort weiterverwendet zu werden, sofern und solange sie mangels C-Kleinspeicherkapazität nicht durch hinzukommende Daten hinausgedrängt würden. Zwar gibt es inzwischen ein hierarchisches Cache-Speicher-Angebot, nachdem man wenigstens erkannt hat, dass mithilfe von Algorithmen der Linearen Algebra wie z.B. der Matrixvektormultiplikation gezielt Effizienz-differenzen generiert werden können, je nachdem, ob auch die Summe aller momentan zu verarbeitenden Daten in den Cache passt. Sofern nicht, müsste man diese Daten zeitaufwendig mehrfach nachladen (cache-fault). Genau so etwas könnte durch Matrizen/Vektoraufteilung in kleinere Datenschübe vermieden werden.
Als banales Handycape beim üblichen Entwickeln von Algorithmen gilt die häufig entstehende Abhängigkeit von Zwischen-ergebnissen durch standardisiertes, d.h. bedarfsneutrales Verarbeiten. Anders ausgedrückt, erzeugt der Parallelalgorithmus eine standardisierte Datenverarbeitung, unterdes aber viele dieser Daten allzu unterschiedlich sind, als dass sie überwiegend standardisiert verarbeitet werden dürften. Diese Mixtur aus Datenverzerrung und Datenfehlsteuerung schafft jene zeit- und energie-fressenden Abhängigkeiten, die sich sodann in Datenkanalverstopfungen niederschlagen. Eine solche Parallelisierung kann bspw. mithilfe der linearen Rekursion vermieden werden: (ai,bi ∈R) mit x1:=a1andxi:=bixi−1+ai,i=2,...,n.
Erklärung der Formel: für bi ≡ 1 steht zunächst eine einfache Summe. Hingegen wird suggeriert, dass xn erst dann berechnet werden könnte, sofern auch wenn xn−1 bekannt sei. Dies würde tatsächlich den Aufwand von n Zeitschritten zur Folge haben (was bei näherem Hinschauen nicht der Fall ist). In Wahrheit nämlich wird die Berechnung in log2 n Zeitschritten ermöglicht, sofern man n Prozessoren verwendet. Anhand dieser Präergebnisse x2 = a2 + b2a1, x3 = a3 + b3a2 + b3b2a1, x4 = a4 + b4a3 + b4b3a2 + b4b3b2a1 wird folg. Allgemeindarstellung erkennbar. S.Abb.r.:

Dieser Zwischenformel liegt das rekursive Verdopplungsverfahren sonach zugrunde, welches nun für n = 8 = 2(hoch3) vollführt wird. Schließlich ließe sich auch das Ergebnis x8 Dieser Zwischenformel liegt das rekursive folgenderweise klammern:

Ferner ließe sich mit p = 7 Prozessoren schon in 3 = log2 8 Schritten berechnen, allerdings unter simplifizierter Prämisse, dass pro Schritt immer nur eine Multiplikation (axpy-Operation) folgenderweise durchgeführt werden kann: y := ax + y. Während im Computer allg. die Variablen einfach überschrieben, d.h. übertüncht werden, sind die relevanten Zwischenergebnisse hier jw. mit Apostrophs versehen: Dieser Lösungsweg korreliert infolge auch mit der vorangestellten respektive nachstehenden Klammerung:

Schon in diesem Beispiel lassen sich typische Eigenschaften von Parallelalgorithmen erkennen:
-
Zur sequentiellen Rekursion bedarf es n−1 axpy-Operationen, zur rekursiven Verdopplung hingegen rd. doppelt so viele. Folglich benötigt der Parallelalgorithmus eine deutlich höhere sequentielle Laufzeit als der sequentielle selbst.
-
Würde man optional über deutliche mehr Prozessoren verfügen, so wäre trotzdem eine signifikante Einsparung der Laufzeit unter nicht möglich, da eben dieser Algorithmus aufgrund seines Parallelisierungsgrads immerzu begrenzt ist.
-
Während in Schritt 1 noch alle 7 benötigten Prozessoren verwendet wurden, verbleiben in Schritt 2 bloß noch drei, sonach das Endergebnis nur noch durch einen einzigen Prozessor errechnet wird. Auch hier wird die ungünstige Verteilung der jeweiligen Belastungen wiederum erkennbar.
Alle 3 Punkte treten regulär bei größeren Problemen auf und sorgen dafür, dass bei Einsatz von p Prozessoren niemals nur 1/p-Faches der ursprünglichen Laufzeit vonnöten ist. Welch eine Zeit- und Energievergeudung! Des einfacheren Verständnisses halber weiter in Englisch:
All 3 issues appear on a regular basis in the context of more extensive problems and are responsible for the fact that when using p processors, the multiple of 1/p of the original runtime will never be necessary. What a waste of time and energy! The following fundamental ideas have been worked out in further detail using advanced matrix vector multiplications (s. formula) →
in treatises that analyze this in more depth. If necessary, supplementary information packages are added, provided that their applicability correlates with the intelligibility of the one using them. That means that always, and only if, the guiding principle of the company that benefits from our research results are in line with the goals for the common good of FEAT, the practical solutions of our scientific research work will be made available.


See below an arbitrary numerical example with simplified analog graphics:





Explanation:
From the point of view of the periodic functions sine and cosine, the most natural number is not 1 but 2π because it holds: 1) sin(x + 2π) = sin(x) || 2) cos(x + 2π) = cos(x). For all real numbers x and 2π, however, is the smallest number of this property. We call them the period (or period length) of the sine and cosine functions. See diagrams of the 2 functions, relating to each other through a simple relationship: cos(x) = sin(x + π/2). In that sense, they are just "shifted" versions of each other. If the variable “x” has the meaning of time (or a quantity that is proportional to time) traversing uniformly from left to right in the above diagram, the

behavior of the function values describes a regular, i.e. harmonic up and down, between the values –1 and +1. Twice as fast operations are described by the functions sin (2x) and cos (2x), three times as fast operations by the functions sin (3x) and cos (3x), etc.
For this we choose the function which is constant 1. All these functions together are the trigonometric basis functions for period 2π. Let's summarize: A) 1 (constant function), B) cos(nx) for n = 1, 2, 3, ... C) sin(nx) for n = 1, 2, 3, ... The constant function 1 belongs in a certain way to the group of cosine functions, since we can regard it as a special case of cos (nx) with n = 0 (remember, that cos (0) = 1). For the functions sin (nx), however, we would only get the constant function 0 with n = 0. [See the next diagrams]:
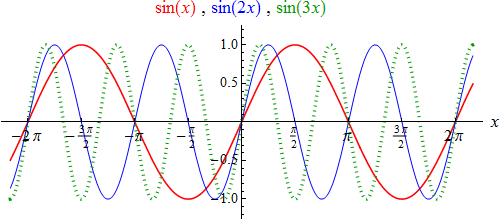
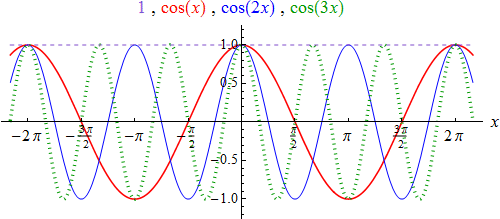
The graphs of the functions sin (nx) and cos (nx) for n > 1 are obtained from those of sin (x)|cos (x) by corresponding "upsets" in the “x”-direction. If we think of x as time, then match:
sin (x) and cos (x) of the fundamental of a system (with period 2π),
sin (2x) and cos (2x) of the first harmonic (they have the period π and hence the period 2π),
sin(3x) and cos (3x) of the second harmonic (they have the period 2π/3 and hence the period 2π), etc.
Although the higher basis functions have smaller period lengths than sin (x) and cos (x) – and the constant function 1 has each number as period length – but in the following considerations we always use 2π as the base period to which we refer: considering each interval, the length of which coincides with period 2π, there is the same amount of surface area as above the x-axis.
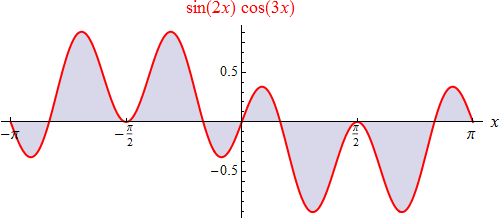
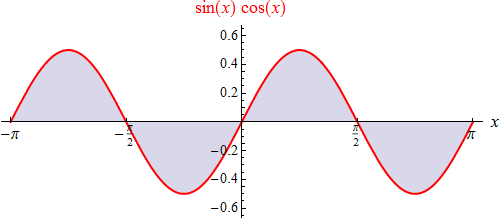
Since the specific integral measures the oriented surface area between graph & x-axis (ie evaluates surface areas below x-axis negatively), it’s obvious that {c + 2π /∫ sin (x) cos (x) dx/c} = 0, regardless of which value is assumed for the lower c-limit. Usually, in such expressions, the interval is chosen to be symmetrical with respect to the zero point, ie c = –π is set, whereby this shape will be accepted: {π/∫ sin (x) cos (x) dx/– π} = 0. We could do the same with any 2 of 4 basic functions as long as they are different: for example, the graph of the product sin (2x) cos (3x) looks like this one on the left.
In the following we consider the “sawtooth function” defined in our base interval by f(x) = x für –π < x < π and is periodically continued on all ℝ…see this graph:
It’s discontinuous for all odd multiples of π. Since it’s an antisymmetric function, a0=0 and an=0 for n=1, 2, 3, … So, we only calculate the evolution coefficients bn: bn= 1/π * {π / ∫ x sin(nx) dx/– π} = –[2 (–1)n/n].

Only in the vicinity of the points of discontinuity, there is still some restlessness that does not correspond to the course of the sawtooth function. By adding more terms, we can push them together, but not completely get rid of them, as long as we only work with finite rows. In short: the series then converges everywhere except at the points of discontinuity against the given function.

From this formula we take the values of the first 4 coefficients b1 = 2, b2 = –1, b3 = 2/3 and b4 = –1/2. The trigonometric polynomial (“g4”) consisting of the corresponding four terms already approximates the “sawtooth function” in a recognizable manner, although not precisely. (See graph on the left). The trigonometric polynomial g10, which consists of the first 10 terms, is already approaching the sawtooth function as seen here:
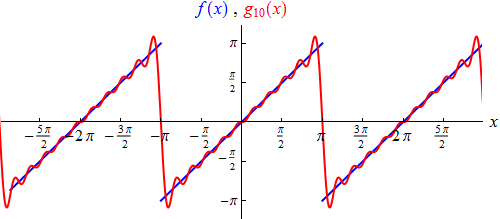

Finally: the next / last graph is continuous in every point, but not differentiable at any point. For example, based on these simplified visualizations, an IT frequency – created by FEAT – would be formulated as follows:
At the points of discontinuity it converges – as already mentioned above – to the mean value of left-sided and right-sided limit of the given function, ie against the value 0. The graph of the function represented g∞ thus looks like the next graph. This agrees with that of the sawtooth function except at the points of discontinuity where we have not fixed it.
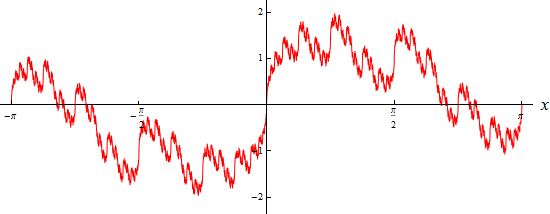

The following arbitrarily outlined graphics illustrate some of our usable IT inter-frequencies from a different perspective. The. compatibility linebetween existing and new inter-frequency runs exactly through the "middle":





Overall, the following is stated: By virtue of this new log-integral algorithm, the performance capacity of the individual computer increases immensely. At the same time, this new frequency key ensures completely hacker-resistant security by means of a 2-fold or even x-fold component encryption (+ op. cit. “compatibility line”). For reasons of know-how protection, only hints are given here without having to disclose the top-secret formulas.
Courtesy of: © LP, 03/12/2019
WEITER ZU FORSCHUNGSAUSBLICK